Overview
The Transformer architecture consists of an encoder-decoder structure. The encoder processes the input sequence by applying multiple layers of self-attention and feed-forward neural networks. Each layer in the encoder attends to all positions in the previous layer, allowing the model to capture both local and global dependencies. The self-attention mechanism assigns weights to different elements in the input sequence based on their relevance to each other, enabling the model to focus on important information. The decoder, on the other hand, takes the encoded representation from the encoder and generates the output sequence step by step. It also utilizes self-attention layers along with encoder-decoder attention layers. The encoder-decoder attention allows the decoder to attend to different parts of the input sequence while generating the output, enabling the model to capture the context and dependencies between the input and output. One of the significant advantages of the Transformer architecture is its ability to parallelize computations. Unlike recurrent models that process input sequentially, Transformer can process all elements in the sequence simultaneously, making it highly efficient for training and inference on modern hardware. The Transformer architecture, with its self-attention mechanism and parallel processing capabilities, has achieved remarkable success in various natural language processing tasks such as machine translation, language modeling, text generation, and question answering. It has become the foundation for many state-of-the-art models and has greatly advanced the field of deep learning in natural language processing.
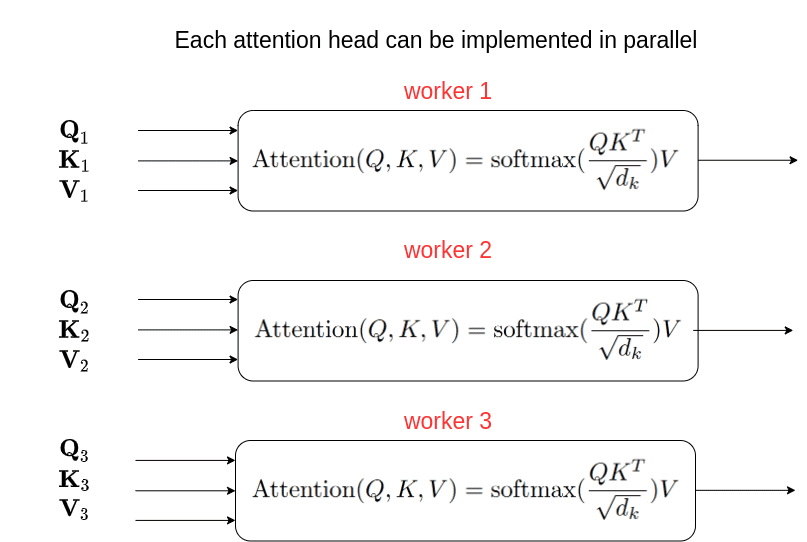
Self-attention is a crucial component of the Transformer architecture that enables the model to capture dependencies and relationships among input elements effectively. It allows the model to assign different weights or attention scores to each element in the input sequence, indicating its importance for making predictions. In self-attention, the input sequence is transformed into three different representations: query, key, and value. These representations are obtained by applying linear transformations to the input. The attention mechanism then computes the attention scores between each query and key pair, indicating how much attention should be given to each element. The attention scores are computed using a similarity function, such as dot product or scaled dot product, followed by a softmax operation to obtain a probability distribution over the keys. The values corresponding to the keys are then weighted by their attention scores and summed up to produce the final output. By allowing the model to attend to different parts of the input sequence, self-attention enables the Transformer to capture long-range dependencies and contextual information efficiently. It overcomes the limitations of recurrent models that process input sequentially and may struggle with long-term dependencies. The parallel processing nature of the Transformer architecture further enhances its efficiency. Since self-attention does not depend on the order of input elements, the Transformer can process the entire sequence in parallel, making it highly suitable for both training and inference on modern hardware, such as GPUs. The combination of self-attention, parallel processing, and multiple layers of the Transformer architecture has led to significant advancements in natural language processing tasks, including machine translation, text generation, sentiment analysis, and more. The Transformer has become a foundational model in the field and continues to inspire further research and innovation.
Learn about the Working PrincipleWorking Principle
The key component of the Transformer architecture is the self-attention mechanism. It allows the model to focus on different parts of the input sequence to capture dependencies and relationships effectively. In self-attention, each input element is associated with three vectors: Query (Q), Key (K), and Value (V). The attention score between two elements is calculated as the dot product of the Query and Key vectors, divided by the square root of the dimension of the vectors. This score determines the importance or relevance of one element to another. The attention scores are then scaled using the softmax function to obtain weights. These weights are used to linearly combine the Value vectors, producing the final output of the self-attention mechanism. The self-attention mechanism allows the model to attend to different parts of the input sequence and capture both local and global dependencies. It provides a powerful way to model relationships between elements in the sequence, facilitating better representation learning. In the Transformer architecture, self-attention is applied in multiple layers, allowing the model to capture complex dependencies and make more informed predictions. This, combined with the encoder-decoder structure and additional components such as positional encoding and feed-forward neural networks, has made the Transformer highly successful in various natural language processing tasks, including machine translation, text generation, and language understanding.
Transformer consists of an encoder-decoder structure. The encoder takes the input sequence and applies multiple layers of self-attention and feed-forward neural networks. Each layer in the encoder attends to all positions in the previous layer, enabling the model to capture both local and global dependencies.
The decoder takes the encoded representation and generates the output sequence step by step. It also utilizes self-attention layers along with encoder-decoder attention layers to attend to different parts of the input and output sequences during the decoding process.
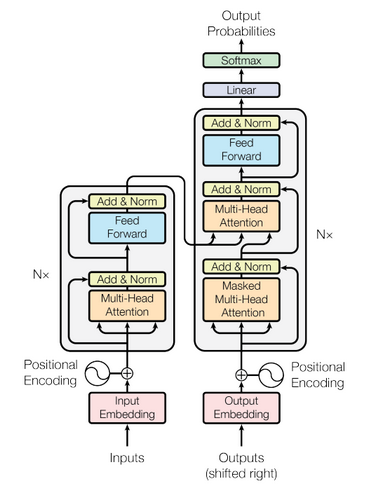
The self-attention mechanism in Transformer allows the model to capture long-range dependencies and handle variable-length sequences effectively. By attending to different parts of the input sequence, the model can learn complex relationships and make accurate predictions.
The self-attention mechanism is computed using the following formulas: