Overview
Recurrent Neural Network (RNN) is a deep learning algorithm widely used in sequence data processing tasks. It leverages its recurrent structure to model temporal information in the data, making it suitable for natural language processing, speech recognition, time series prediction, and more.
RNN is inspired by the biological neural circuitry and exhibits a certain level of memory when processing sequences. Unlike traditional neural networks, RNN receives an input and the hidden state from the previous time step at each time step and computes the current hidden state. The hidden state can be seen as the network's encoding or memory of past information. Then, based on the current hidden state, RNN generates an output and updates the hidden state, passing it to the next time step.
Learn about the Working PrincipleWorking Principle
The key to RNN is its recurrent structure, which allows information to be propagated and retained within the network. RNN consists of a hidden state and an output layer.
At each time step, RNN takes an input and the hidden state from the previous time step as input and computes the current hidden state. The hidden state can be considered as the network's encoding or memory of past information. Then, based on the current hidden state, RNN produces an output and updates the hidden state, which is then passed to the next time step.
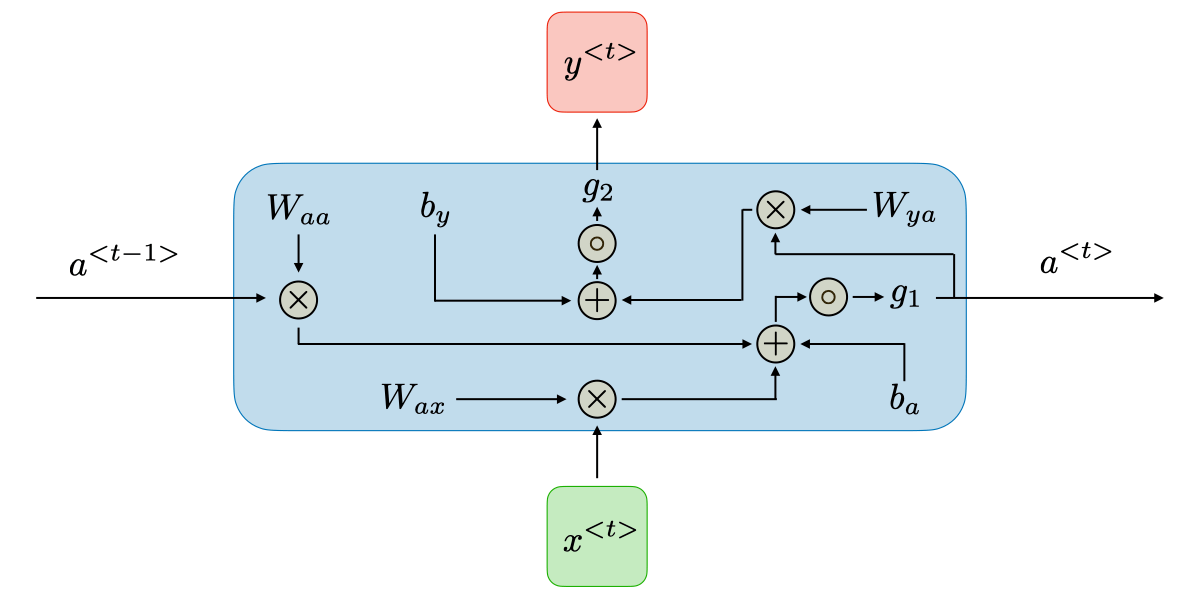
The hidden state in RNN is recurrently passed through the network, allowing the network to process each element in the sequence while maintaining the continuity of context information. This memory capability makes RNN suitable for handling sequence data with long-term dependencies.
In addition to the standard RNN, there are variants based on RNN, such as Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU), which improve the modeling capability of long-term dependencies by introducing gating mechanisms.
Long Short-Term Memory (LSTM)
LSTM is a type of RNN architecture that addresses the vanishing gradient problem and allows the network to learn long-term dependencies effectively. It introduces memory cells and three gating mechanisms: the input gate, forget gate, and output gate.
The input gate determines which information should be stored in the memory cell, while the forget gate controls the information to forget from the memory cell. The output gate regulates the output based on the current hidden state and the memory cell.
By selectively updating and forgetting information, LSTM can retain relevant information over long sequences, making it well-suited for tasks involving long-term dependencies, such as speech recognition, language modeling, and sentiment analysis.
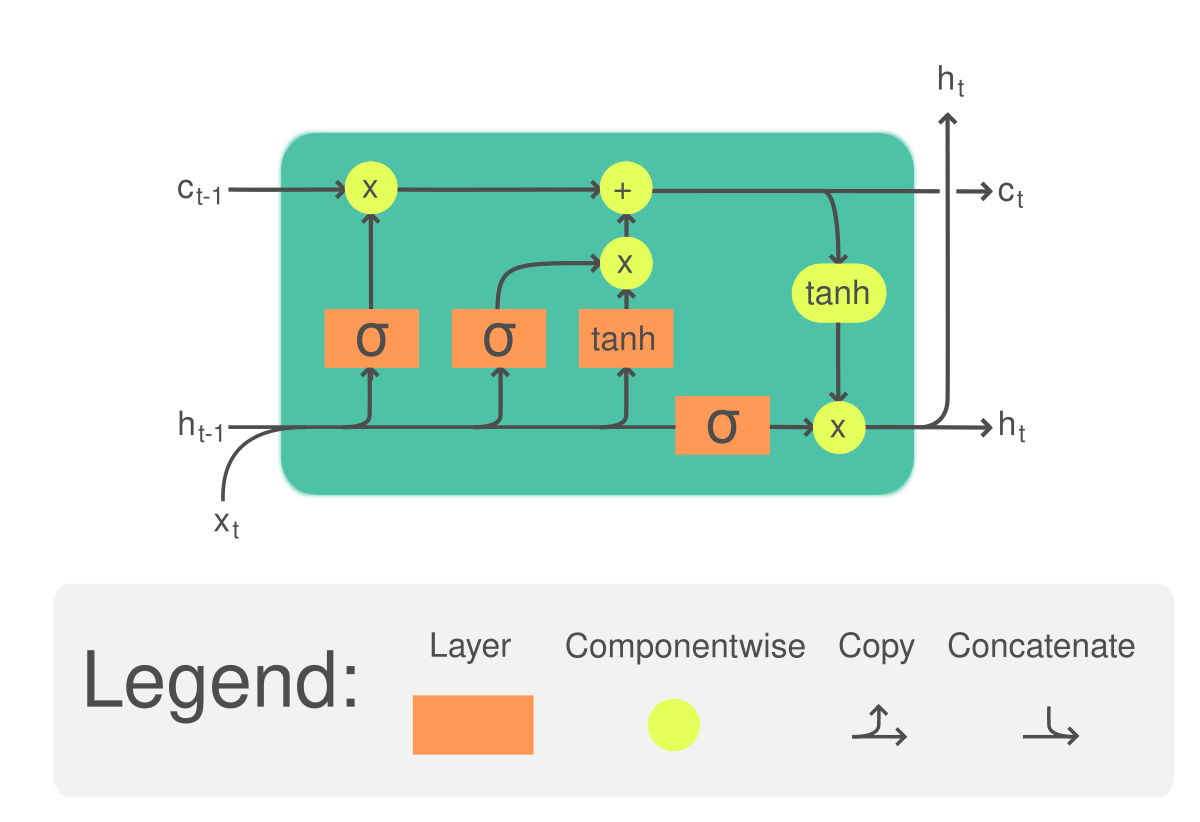
Gated Recurrent Unit (GRU)
GRU is another variant of RNN that addresses the vanishing gradient problem and captures long-term dependencies. It simplifies the LSTM architecture by combining the forget and input gates into an update gate and merging the cell state and hidden state.
The update gate controls the amount of old information to retain and the amount of new information to incorporate. GRU also introduces a reset gate, which determines the extent to which the past information should be ignored.
By using fewer gating mechanisms than LSTM, GRU simplifies the network architecture and reduces computational complexity. It performs well in tasks requiring modeling of long-term dependencies, such as machine translation, speech recognition, and video analysis.
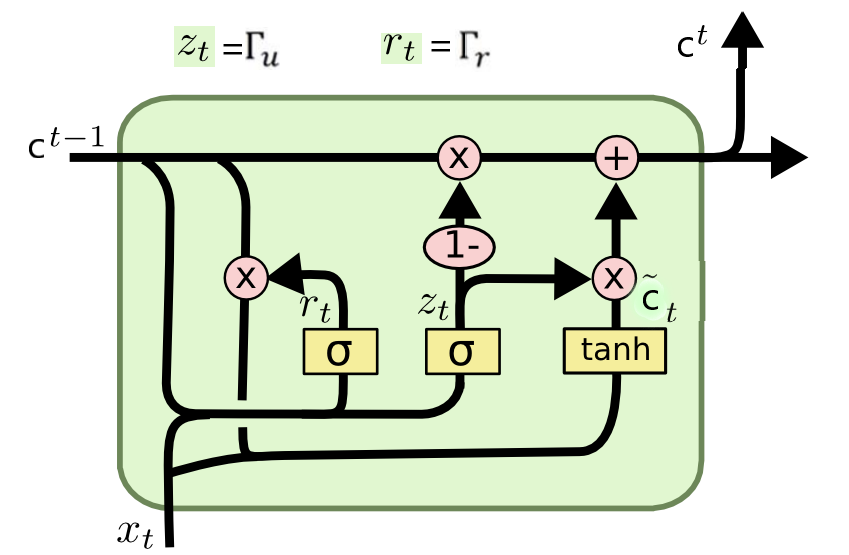
Differences and Advantages
- LSTM addresses the vanishing gradient problem and enables the modeling of long-term dependencies effectively.
- It introduces memory cells and three gating mechanisms (input gate, forget gate, and output gate) to control information flow.
- LSTM is well-suited for tasks involving long-term dependencies, such as speech recognition, language modeling, and sentiment analysis.
LSTM (Long Short-Term Memory)
- GRU simplifies the LSTM architecture by combining the forget and input gates into an update gate and merging the cell state and hidden state.
- It introduces a reset gate to determine the extent to which past information should be ignored.
- GRU offers a simpler network architecture and reduced computational complexity compared to LSTM.
- It performs well in tasks requiring modeling of long-term dependencies, such as machine translation, speech recognition, and video analysis.
GRU (Gated Recurrent Unit)
- RNN is the most basic form of the recurrent neural network architecture.
- It receives an input and the hidden state from the previous time step at each time step and computes the current hidden state.
- RNN exhibits memory capabilities and is suitable for sequence data processing tasks.
- However, it can suffer from the vanishing gradient problem, limiting its ability to capture long-term dependencies.
RNN (Recurrent Neural Network)
