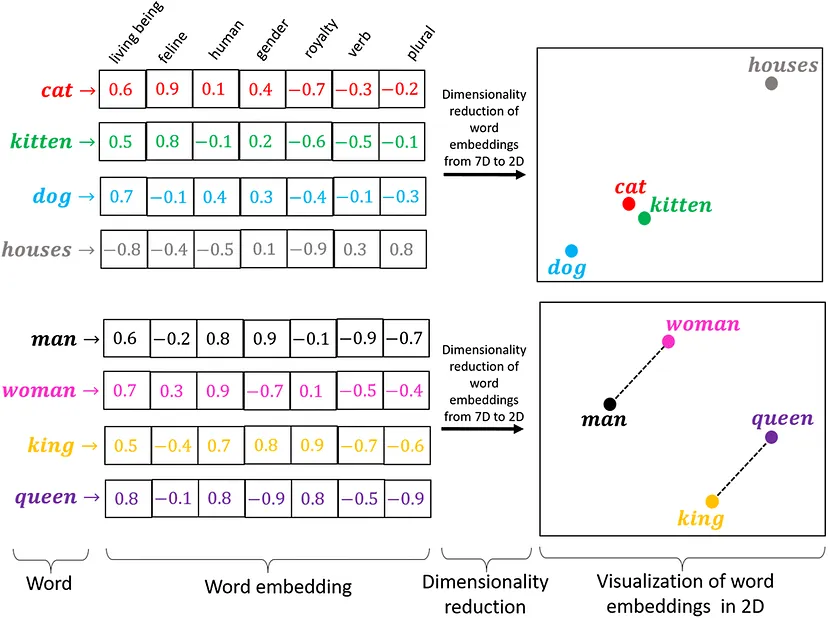
Word
1.1 Word Separation
Word Separation, also known as Word Tokenization, is the process of dividing a text or sequence of characters into individual words. The principles behind word separation can vary depending on the specific language and the desired level of granularity. In general, the following principles are commonly applied:
- Whitespace-based separation: This principle involves splitting the input text based on whitespace characters such as spaces, tabs, or line breaks. It assumes that words are separated by these whitespace characters.
- Punctuation-based separation: This principle involves using punctuation marks as delimiters to separate words. Common punctuation marks used for word separation include periods, commas, exclamation marks, and question marks.
- Language-specific separation rules: Different languages may have specific rules for word separation. For example, in some languages, compound words are formed by combining multiple words without whitespace in between. Language-specific rules take into account these linguistic conventions to accurately separate words.
Word separation has numerous applications in natural language processing and text analysis. Some of the key applications include:
- Part-of-speech tagging: Word separation is essential for identifying and labeling the parts of speech of individual words, which is crucial for syntactic and semantic analysis of sentences.
- Text normalization: Word separation helps in standardizing the representation of words, which is important for various text processing tasks, including machine translation, information retrieval, and sentiment analysis.
- Language modeling: Accurate word separation is essential for building language models that capture the statistical properties of word sequences, enabling applications such as speech recognition and machine translation.
Here's an example to illustrate word separation:
Input Text: "NaturalLanguageProcessing"
Separated Words: "Natural", "Language", "Processing"
1.2 Word Annotation
Word Annotation is the process of assigning additional information or metadata to individual words in a text. It involves labeling words with their part-of-speech (POS) tags, syntactic dependencies, or semantic categories to enhance the understanding of the text. The principles and techniques used for word annotation depend on the specific annotation scheme and the desired level of linguistic analysis. Here are some common principles of word annotation:
- Part-of-speech (POS) tagging: POS tagging is a widely used form of word annotation, where each word is assigned a grammatical category such as noun, verb, adjective, or adverb. This information helps in understanding the syntactic structure and grammatical relationships within a sentence.
- Syntactic annotation: Syntactic annotation involves identifying the syntactic dependencies between words in a sentence. It includes labeling words as subjects, objects, modifiers, or other grammatical roles to capture the hierarchical structure of the sentence.
- Semantic annotation: Semantic annotation focuses on assigning meaning or semantic categories to words. This can involve labeling words with their named entity types (e.g., person, location, organization), sentiment polarity (positive, negative, neutral), or other semantic attributes.
Word annotation has various applications in natural language processing and text analysis. Some of the key applications include:
- Syntax and grammar analysis: Word annotation enables the analysis of sentence structure, syntactic relationships, and grammatical correctness. It is crucial for tasks such as parsing, syntactic parsing, and grammar checking.
- Information extraction: Annotated words provide valuable information for extracting structured data from unstructured text. Named entity recognition, relation extraction, and event extraction are some examples of information extraction tasks that rely on word annotation.
- Machine translation and language generation: Word annotation facilitates the development of language models and translation systems. It helps in disambiguating word senses, improving translation accuracy, and generating coherent and grammatically correct text.
Here's an example to illustrate word annotation:
Input Text: "I saw a cat chasing a mouse."
Annotated Words: "I" (PRON), "saw" (VERB), "a" (DET), "cat" (NOUN), "chasing" (VERB), "a" (DET), "mouse" (NOUN), "." (PUNCT)

1.3 Entity Recognition
Entity Recognition, also known as Named Entity Recognition (NER), is the process of identifying and classifying named entities in a text. Named entities refer to real-world objects such as persons, locations, organizations, dates, and other types of named entities depending on the application domain. Here are some principles of entity recognition:
- Pattern-based matching: Entity recognition often involves using predefined patterns or rules to identify entities. These patterns can be based on regular expressions, grammatical structures, or other language-specific rules.
- Statistical models: Machine learning techniques, such as statistical models (e.g., conditional random fields, recurrent neural networks), can be employed for entity recognition. These models learn patterns from annotated training data and then use that knowledge to predict entities in new texts.
- Hybrid approaches: Some entity recognition systems combine rule-based approaches with statistical models to achieve higher accuracy. These systems leverage the strengths of both approaches to handle different types of entities and variations in text.
Entity recognition has various applications in natural language processing and text analysis. Some of the key applications include:
- Information extraction: Entity recognition plays a crucial role in extracting structured information from unstructured text. It helps in identifying relevant entities for further analysis, such as extracting product names, person names, or organization names from text.
- Question answering: Entity recognition is important for answering questions that require specific named entity information. For example, given a question like "Who is the CEO of Apple?", entity recognition can help identify the entity "Apple" as an organization and retrieve the corresponding CEO information.
- Text classification: Entity recognition can contribute to text classification tasks by identifying important entities that can serve as features or indicators for classification. For example, in sentiment analysis, recognizing person names or product names can provide valuable information for sentiment classification.
Here's an example to illustrate entity recognition:
Input Text: "Apple Inc. is planning to open a new store in New York."
Recognized Entities: "Apple Inc." (ORGANIZATION), "New York" (LOCATION)

1.4 Keyword Extraction
Keyword Extraction is the process of identifying the most relevant and important words or phrases from a text. Keywords represent the main topics or themes discussed in the text and can provide a summary or highlight the key points. Here are some principles of keyword extraction:
- Term frequency: Keyword extraction often relies on the frequency of terms in the text. Words that occur more frequently are considered more important and likely to be keywords.
- TF-IDF: Term Frequency-Inverse Document Frequency (TF-IDF) is a popular technique used for keyword extraction. It takes into account both the term frequency in the current document and the inverse document frequency across a collection of documents to identify significant words.
- Graph-based algorithms: Graph-based algorithms, such as TextRank or YAKE, construct a graph representation of the text, where words or phrases are nodes, and the edges represent their relationships. The importance of a word is determined by its centrality within the graph.
Keyword extraction has various applications in natural language processing and text analysis. Some of the key applications include:
- Information retrieval: Keyword extraction can help improve information retrieval systems by indexing documents based on their keywords. It enables efficient searching and retrieval of relevant documents based on user queries.
- Text summarization: Extracting keywords from a text can provide a summary or overview of the main topics discussed. This is particularly useful for generating automatic summaries or extracting key points from lengthy documents.
- Content analysis: Keyword extraction is valuable for analyzing large collections of text, such as social media data or customer reviews. It helps identify the most frequently mentioned topics, enabling businesses to gain insights from unstructured textual data.
Here's an example to illustrate keyword extraction:
Input Text: "Natural Language Processing (NLP) is a subfield of artificial intelligence that focuses on the interaction between computers and humans."
Extracted Keywords: "Natural Language Processing", "subfield", "artificial intelligence", "interaction", "computers", "humans"

1.5 Useless Word Filtering
Useless Word Filtering, also known as Stop Word Filtering, is the process of removing common words that do not carry significant meaning in a text. These words, often referred to as stop words, include common articles, prepositions, pronouns, and other frequently occurring words that do not contribute to the core content or the overall understanding of the text. Here are some principles of useless word filtering:
- Predefined lists: Stop words can be filtered based on predefined lists of commonly occurring words. These lists are language-specific and contain words that are considered non-informative in most contexts.
- Contextual filtering: Useless word filtering can be performed by considering the specific context or domain of the text. Certain words that might be considered stop words in general might have significance in certain domains, and vice versa.
- Customization: Users have the flexibility to customize the list of stop words based on their specific requirements or domain knowledge. This allows for better adaptation to the particular text analysis task.
Useless word filtering has various applications in natural language processing and text analysis. Some of the key applications include:
- Text mining: Useless word filtering is crucial in text mining tasks such as document clustering, topic modeling, and sentiment analysis. By removing non-informative words, it helps in focusing on the meaningful content and extracting key insights from text data.
- Search engine optimization (SEO): Filtering stop words can improve search engine optimization by reducing the noise and improving the relevance of indexed content. It helps search engines better understand the main keywords and topics of a webpage.
- Information retrieval: Useless word filtering improves the efficiency and effectiveness of information retrieval systems by eliminating common words that do not contribute to the retrieval process. This results in more accurate and targeted search results.
Here's an example to illustrate useless word filtering:
Input Text: "The quick brown fox jumps over the lazy dog."
Filtered Text: "quick brown fox jumps lazy dog."