Overview
Convolutional Neural Network (CNN) is a deep learning algorithm widely used in image recognition and computer vision. It simulates the human visual system to automatically extract features from images and is applied in tasks such as classification, object detection, and face recognition.
CNN's inspiration from the biological visual system, specifically the human visual cortex, allows it to mimic the way humans perceive and process visual information. The human visual cortex consists of multiple interconnected layers that progressively analyze visual stimuli, extracting and integrating features to form a rich representation of the input. Similarly, CNNs employ a hierarchical structure with different layers to analyze images. Convolutional layers perform local receptive field operations, where small filters scan the input image to detect patterns and extract local features. These filters capture various aspects of the image, such as edges, corners, and textures. By stacking multiple convolutional layers, CNNs can learn increasingly complex and abstract features. Pooling layers play a crucial role in downsampling the feature maps produced by the convolutional layers. They aggregate information from neighboring pixels, reducing the spatial dimensions of the feature maps while retaining the most relevant information. This downsampling process helps to make the network invariant to small translations and improves computational efficiency. Fully connected layers are responsible for high-level reasoning and decision-making. They receive the extracted features from the previous layers and map them to the output classes or labels. Each neuron in the fully connected layer connects to all neurons in the previous layer, enabling complex relationships and non-linear mappings to be learned. The hierarchical arrangement of convolutional, pooling, and fully connected layers allows CNNs to learn increasingly abstract and discriminative features. The lower layers capture low-level features like edges and textures, while the higher layers learn more complex representations that are specific to the task at hand. This hierarchical feature extraction process enables CNNs to effectively process and classify complex image data, making them highly suitable for a wide range of computer vision tasks.
Learn More about Working PrincipleWorking Principle
CNN consists of convolutional layers, pooling layers, and fully connected layers.
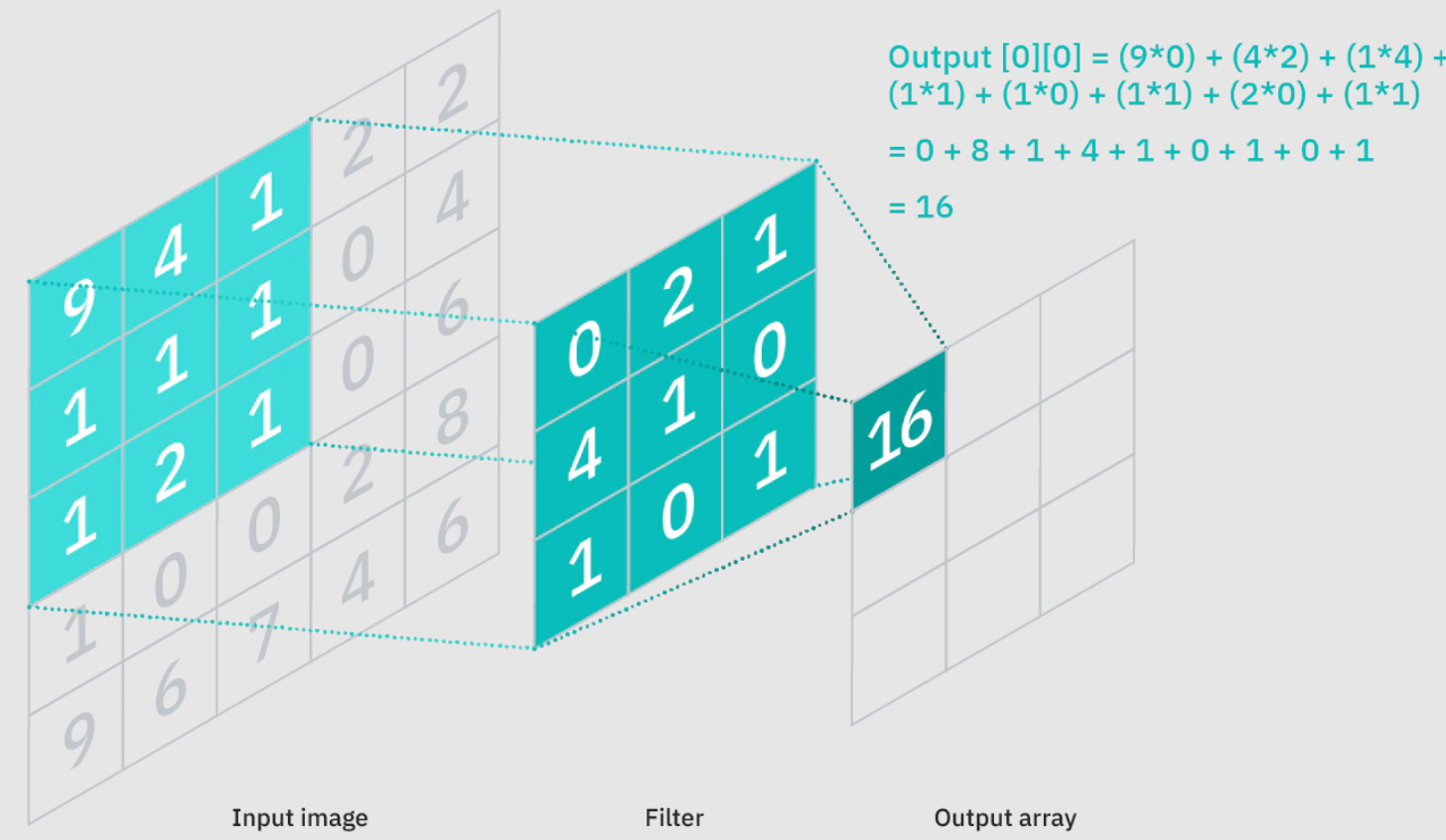
The convolutional layer applies a set of learnable filters (also known as convolutional kernels) to the input image. Each filter is a small matrix of weights that is convolved with the input image by sliding it over the image spatially. At each position, the filter computes the element-wise product between its weights and the corresponding input values and sums up the results to produce a single value in the output feature map. By applying multiple filters, the convolutional layer can learn to detect different features at different spatial locations in the input image. Each filter specializes in detecting a specific pattern or feature, such as edges in different orientations or textures of various scales. Through the process of training, the network automatically learns the optimal values for the filter weights, allowing it to extract relevant features from the input images. The output of the convolutional layer is a stack of feature maps, where each map represents the response of a specific filter to the input image. These feature maps capture different aspects of the input image and encode local information about patterns and structures. Additionally, the use of non-linear activation functions, such as ReLU (Rectified Linear Unit), introduces non-linearities into the network, enabling it to learn more complex and expressive representations. The convolutional layer's ability to perform local receptive field operations and learn spatial hierarchies of features is what makes CNNs particularly effective for image processing tasks. By stacking multiple convolutional layers, the network can learn increasingly abstract and higher-level representations of the input images, leading to improved performance in tasks such as image classification, object detection, and semantic segmentation.
The pooling layer is a crucial component in a Convolutional Neural Network (CNN) that follows the convolutional layer. Its main purpose is to reduce the spatial dimensions of the feature maps while retaining the most important information. This reduction in size helps to decrease the computational complexity of the network and reduces the number of parameters, which can prevent overfitting. The pooling operation is typically performed using either max pooling or average pooling. Max pooling selects the maximum value within each pooling region, while average pooling calculates the average value. Both operations are applied independently to non-overlapping regions of the input feature map, known as pooling windows or pooling regions. By applying pooling, the network achieves a form of translational invariance. Translational invariance means that the network's response remains largely unchanged when the input is shifted or translated slightly. This property is beneficial for tasks such as object recognition, where the precise location of an object in an image may vary. Max pooling is particularly effective in capturing the most salient features within a pooling region. It helps to retain the strongest activations, which often correspond to important local patterns or structures in the input feature map. On the other hand, average pooling computes the average value within each pooling region, providing a more smoothed representation of the input. The pooling layer effectively reduces the spatial dimensions of the feature maps, resulting in a downsampling or subsampling of the data. This reduction helps to make the network more robust to small spatial translations or distortions in the input. Furthermore, by reducing the spatial resolution, the pooling layer also reduces the number of parameters in subsequent layers, making the network more computationally efficient.

The fully connected layer, also known as the dense layer, is an essential component of a Convolutional Neural Network (CNN) that follows the convolutional and pooling layers. Its primary function is to perform high-level reasoning and decision-making based on the features extracted from the previous layers. In the fully connected layer, each neuron is connected to every neuron in the previous layer, creating a fully connected network structure. This connectivity enables the network to learn complex nonlinear mappings between the extracted features and the target output classes or labels. Each connection is associated with a weight and a bias, which are learned during the training process. During inference or prediction, the output of the previous layer, typically the flattened feature maps from the pooling layer, is fed into the fully connected layer. Each neuron in the fully connected layer performs a weighted sum of the inputs, applying the learned weights and biases. Additionally, an activation function is applied to the weighted sum, introducing nonlinearity into the network's decision-making process. The activation function used in the fully connected layer is typically a nonlinear function such as the Rectified Linear Unit (ReLU) or the sigmoid function. These activation functions introduce nonlinearity, allowing the network to model complex relationships between the input features and the output classes. The fully connected layer's ability to connect every neuron to all neurons in the previous layer enables the network to capture global relationships and dependencies in the data. By learning the appropriate weights and biases, the fully connected layer can effectively combine and process the extracted features from earlier layers to make the final classification decision. It's worth noting that the number of neurons in the fully connected layer is often reduced as we approach the output layer. This reduction helps to control the number of parameters in the network and prevent overfitting. The final layer in the fully connected layer typically consists of as many neurons as the number of target output classes, and the activation function used is typically softmax, which produces a probability distribution over the classes.

By stacking and combining convolutional layers, pooling layers, and fully connected layers, CNN can learn hierarchical representations of image features and achieve excellent performance in tasks such as classification, object detection, and image generation.